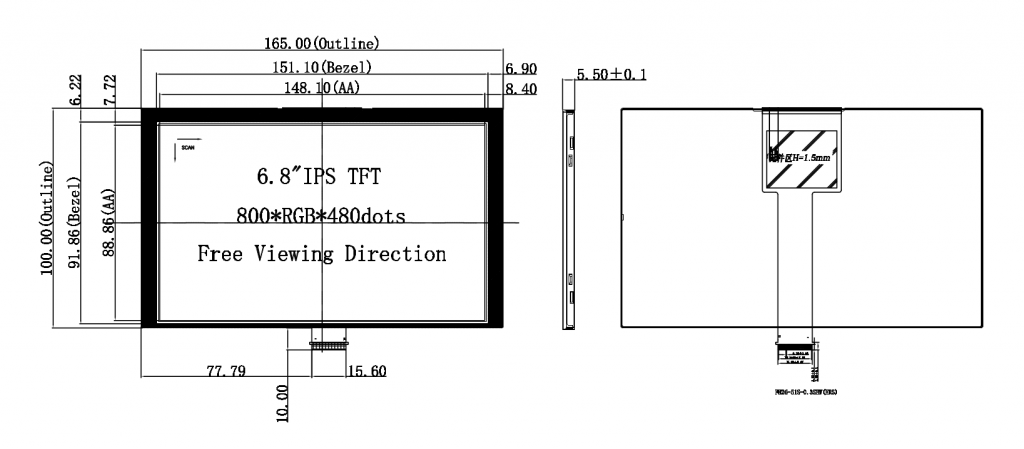
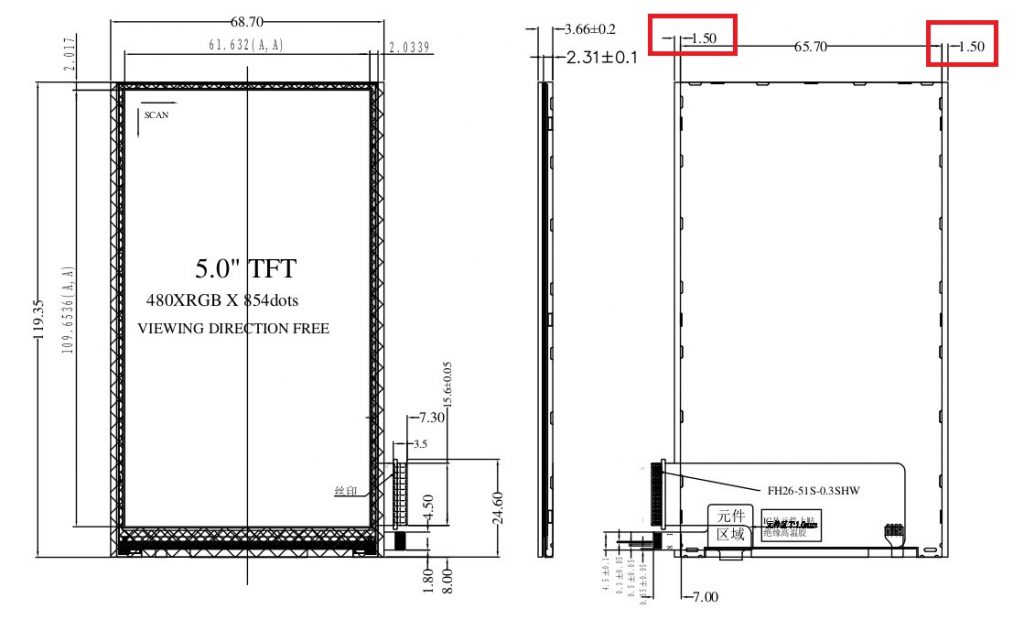
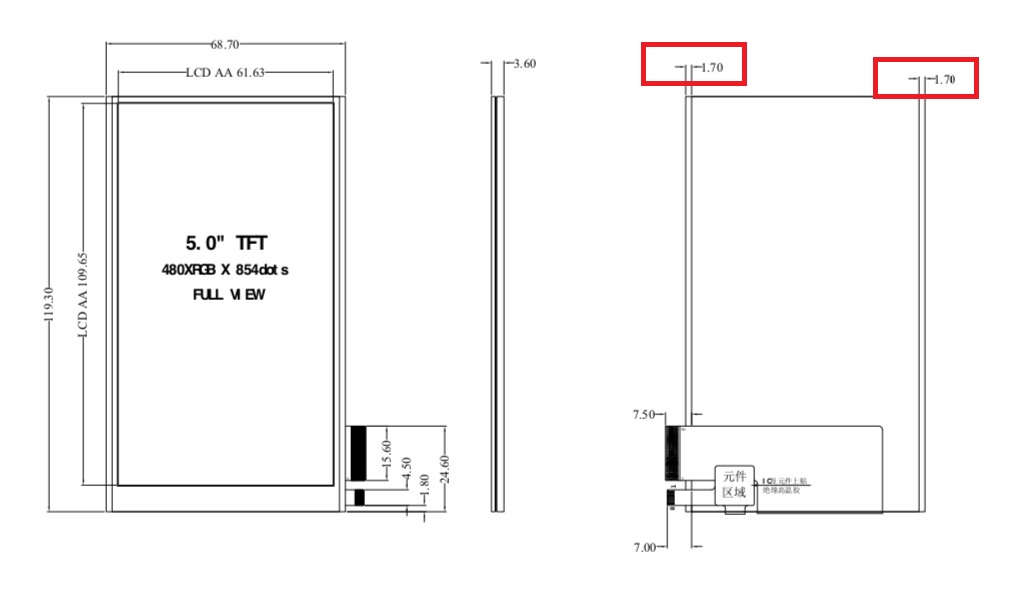
Recently compile openwrt 18.06.9, get this error:
Build dependency: Please install the GNU C Compiler (gcc) 4.8 or later
Build dependency: Please install the GNU C++ Compiler (g++) 4.8 or laterI can not do any further process. But my GCC is pretty new 11.3.0
gcc --version
gcc (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Copyright (C) 2021 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
So its report is absolutely something not right.
PS: I already can image some lazy coder just compare the first byte of gcc version, so it must think my gcc version is ‘1.x’ but not ’11.x’, so report such stupid error.
Easy to fix, just delete the check it will back to work, I have checked by my eye it is 11.x but not 1.x. Sorry about this dirty fix, I am also one of the lazy coder and even worse I am not good at script. :p
--- a/include/prereq-build.mk
+++ b/include/prereq-build.mk
@@ -26,31 +26,12 @@ $(eval $(call TestHostCommand,proper-umask, \
Please build with umask 022 - other values produce broken packages, \
umask | grep -xE 0?0[012][012]))
-$(eval $(call SetupHostCommand,gcc, \
- Please install the GNU C Compiler (gcc) 4.8 or later, \
- $(CC) -dumpversion | grep -E '^(4\.[8-9]|[5-9]\.?|10\.?)', \
- gcc -dumpversion | grep -E '^(4\.[8-9]|[5-9]\.?|10\.?)', \
- gcc --version | grep -E 'Apple.(LLVM|clang)' ))
-
$(eval $(call TestHostCommand,working-gcc, \
\nPlease reinstall the GNU C Compiler (4.8 or later) - \
it appears to be broken, \
echo 'int main(int argc, char **argv) { return 0; }' | \
gcc -x c -o $(TMP_DIR)/a.out -))
-$(eval $(call SetupHostCommand,g++, \
- Please install the GNU C++ Compiler (g++) 4.8 or later, \
- $(CXX) -dumpversion | grep -E '^(4\.[8-9]|[5-9]\.?|10\.?)', \
- g++ -dumpversion | grep -E '^(4\.[8-9]|[5-9]\.?|10\.?)', \
- g++ --version | grep -E 'Apple.(LLVM|clang)' ))
-
-$(eval $(call TestHostCommand,working-g++, \
- \nPlease reinstall the GNU C++ Compiler (4.8 or later) - \
- it appears to be broken, \
- echo 'int main(int argc, char **argv) { return 0; }' | \
- g++ -x c++ -o $(TMP_DIR)/a.out - -lstdc++ && \
- $(TMP_DIR)/a.out))
-
$(eval $(call TestHostCommand,ncurses, \
Please install ncurses. (Missing libncurses.so or ncurses.h), \
echo 'int main(int argc, char **argv) { initscr(); return 0; }' | \PS: I meet tons of problem after this, like m4 compatible error, and gdb8 need python2, so for simple, just download latest openwrt and copy the tools Makefile to replace the old bones, it will back to work.